
直接的集成环境IDEA上连接Spark,运行代码,不用再在服务器上执行代码, 美好的想法,但只成功了一半
1.远程连接的3关
写好代码:
val sparkurl="spark://guan-pc:7077"
val spark = SparkSession.builder.master(sparkurl).appName("start").getOrCreate()1.1 代码工程配置正确
运行错误先是Class Not Found,是工程配置的版本与Spark、Scala不匹配的原因,先要将sbt中的
libraryDependencies += "org.apache.spark" % "spark-streaming_2.12" % "2.4.2" % "provided"的provided部分删除,因为程序是要在本地运行的
然后就是这两个版本了,Spark的版本好办,安装的是什么就写什么。 中间的Scala内核版本就要麻烦点,不要想当然,可靠的办法是去Spark安装目录的jars下面看, Spark2.4.2用的内核版本是2.12,但2.4.3又回到了2.11,想当然会错
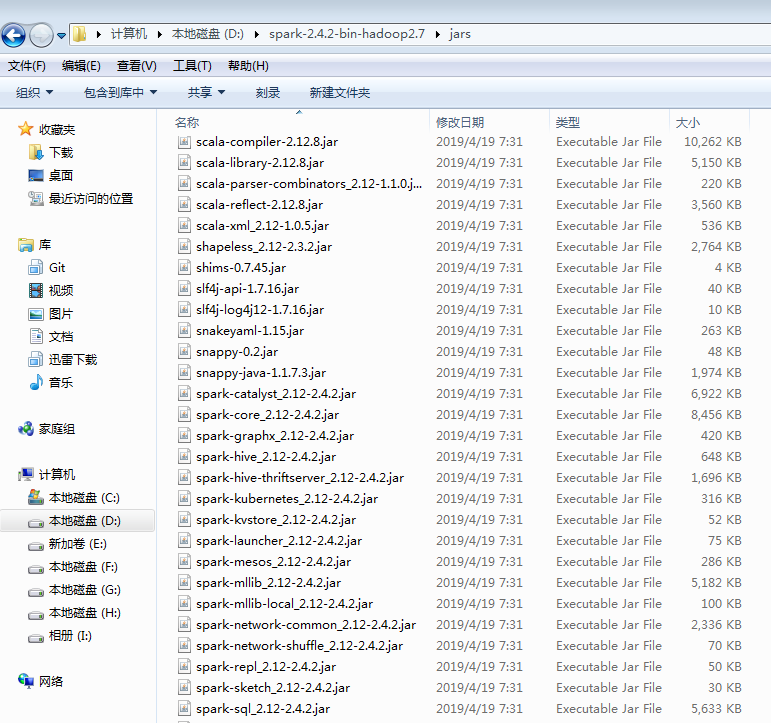
window下如此,Linux同
1.2 HADOOP文件
之后会提示个找不到HADOOP文件winutils.exe,下一个HADOOP的支持目录
1.3 启动Spark的大坑
似乎万事具备了,但实际上就是连不上,还重新检查了Linux端口,无论怎么弄, 网页没问题,但代码就是连不上,终于找到了大神的解决方案,原来是Spark的启动方式, 启动时我一般都用最简单的命令
start-all.sh 但要在windows上远程连接,要用指明IP的方式启动
start-master.sh -h 192.168.0.109
start-slave.sh spark://192.168.0.109:7077终于连接好了,准备开始读数据 ## 2.读文件的方法 还不知道怎么解决,因为代码在本地执行,而Spark在服务器, Spark无法读取本地的文件,代码如何才能告诉Spark读的是服务器文件呢? 试了
spark.read.csv("file:///home/guan/data/dat.csv")还是本地的,难道一定要建个HDFS才行吗? 有待继续研究
3 window上安装spark
在windows上安装Spark没有什么不同,但启动是个问题,start-master,start-all之类的命令在windows上不能用 要调用类的方式启动
spark-class org.apache.spark.deploy.master.Master
spark-class org.apache.spark.deploy.worker.Worker spark://ip:port